
Last updated on 23rd Apr 2025| 9393
- Introduction to Natural Language Processing (NLP)
- What is Lemmatization?
- Difference Between Lemmatization and Stemming
- Importance of Lemmatization in NLP
- Lemmatization Process
- Tools and Libraries for Lemmatization
- Challenges in Lemmatization
- Conclusion
Introduction to Natural Language Processing (NLP)
At the nexus of linguistics, computer science, and artificial intelligence, the area of natural language processing (NLP) seeks to make it possible for machines to comprehend, interpret, and react to human language in a meaningful and practical manner. NLP is the basis for numerous applications, including chatbots, language translation software, and search engines. Data Science Training covers various activities, from text analysis to speech recognition. Fundamentally, NLP addresses issues about the subtleties and complexity of human language. Words, sentences, and phrases can have multiple meanings depending on context, and NLP systems must be able to account for these subtleties. One of the key tasks within NLP is the processing of words. This is where lemmatization comes in. Lemmatization helps machines understand the core meaning of words by reducing them to their base or dictionary form, which is crucial for adequate language understanding and processing.
To Obtain Your Data Science Certificate? View The Data Science Course Training Offered By ACTE Right Now!
What is Lemmatization?
Lemmatization is a text normalization technique used in Natural Language Processing (NLP) to convert words to their base or root form. Unlike stemming, which chops off the ends of words (sometimes resulting in non-existent words), lemmatization ensures that the transformed word is a valid dictionary word. The primary goal of lemmatization is to reduce different inflected forms of a word to a single, standard form. Artificial Intelligence Present and Future is done by considering the word’s meaning and context in a sentence, which helps preserve the word’s intended meaning.
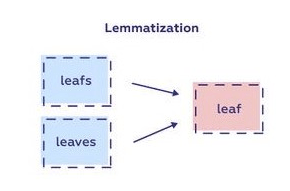
Lemmatization uses vocabulary and morphological analysis to achieve this. It considers a word’s part of speech (POS), such as whether the word is a noun, verb, or adjective, to choose the correct lemma. For example, “ran” (past tense) would be reduced to “run” if it’s a verb but could remain unchanged if the word “ran” is used as a noun (e.g., “a run”).
Difference Between Lemmatization and Stemming
- Stemming reduces words to their root form by chopping off prefixes or suffixes, often resulting in non-existent words, while lemmatization reduces words to their root form based on dictionary meaning, ensuring valid words.
- Stemming uses heuristic methods to remove affixes, such as turning “running” into “run,” while lemmatization uses vocabulary and morphological analysis, considering context and part of speech (e.g., “better” becomes “good”).
- Stemming can be imprecise, sometimes producing incorrect forms like “flies” becoming “fli,” whereas lemmatization is more accurate and contextually appropriate.
- Stemming doesn’t consider context, leading to potential errors, while lemmatization accounts for context and part of speech, ensuring more meaningful reductions.
- Stemming is faster because Bayesian Network in AI relies on simple algorithms, whereas lemmatization is slower due to its need for complex linguistic resources.
- Stemming can produce incomplete or ungrammatical outputs, like “better” becoming “bet,” while lemmatization consistently produces valid and grammatically correct words.
- Stemming is useful for tasks prioritizing speed, such as search engines, while lemmatization is preferred for applications requiring accuracy, such as machine translation or sentiment analysis.
- Finally, stemming requires minimal resources, typically just an algorithm, while lemmatization demands more resources, like dictionaries and part-of-speech tagging.
- from nltk.stem import WordNetLemmatizer
- lemmatizer = WordNetLemmatizer()
- print(lemmatizer.lemmatize(“running”, pos=’v’))
- import spacy
- nlp = spacy.load(“en_core_web_sm”)
- doc = nlp(“running runs”)
- for the token in the doc:
- print(token.text, token.lemma_)
- from text blob import Word
- word = Word(“running”)
- print(word.lemmatize(“v”))
Get Your Data Science Certification, Gain Insights From Leading Data Science Experts And Advance Your Career With ACTE’s Data Science Course Training Today!
Importance of Lemmatization in NLP
Lemmatization plays a crucial role in enhancing text analysis and improving the performance of natural language processing (NLP) models. One key benefit is that it improves search and information retrieval. By reducing words to their base form, lemmatization enables search engines and retrieval systems to return relevant results for words with different inflected forms. For example, a search for “run” can yield results for “running,” “ran,” and “runner” because they all map to the same root. Another significant advantage is in text classification, where lemmatization helps reduce noise from inflected word forms in tasks like sentiment analysis or document classification.
It allows models to focus on the core meaning of words, leading to more accurate classifications. Additionally, machine translation benefits from lemmatization, as it ensures consistent translation of words across languages by reducing them to their base form. Data Science Training, lemmatization supports Named Entity Recognition (NER) by ensuring proper identification of entities, such as cities or organizations, regardless of word variations, enhancing the overall accuracy of NER tasks.

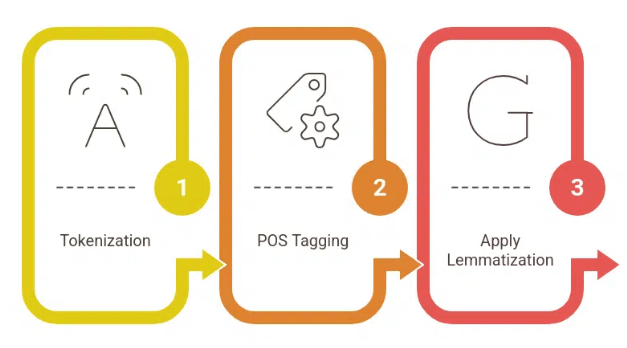
Lemmatization Process
Tokenization
Tokenization is splitting a sentence into individual words (tokens). Tokenization is the first step in any NLP task, breaking the text into manageable units for further processing.
POS Tagging
Once the text is tokenized, the next step is Part-of-Speech (POS) tagging. This step involves identifying the grammatical role of each word (noun, verb, adjective, etc.). Lemmatization requires POS information to reduce a word to its base form accurately.
Applying Lemmatization Rules
After POS tagging, the lemmatizer applies rules to map words to their base forms. A Algorithm in AI rules might include removing suffixes for verbs (e.g., “ed” to make a verb infinitive) or changing irregular forms (e.g., “better” to “good”).
Return Lemmatized Words
Finally, the lemmatized words are returned as the output, ready for further analysis, such as classification, clustering, or sentiment analysis.
Want to Pursue a Data Science Master’s Degree? Enroll For Data Science Masters Course Today!
Tools and Libraries for Lemmatization
NLTK (Natural Language Toolkit)
NLTK is one of the most popular Python libraries for NLP. It provides a simple interface for lemmatization using the WordNet Lemmatizer. Example:
spaCy
spaCy is another powerful NLP library that includes built-in support for lemmatization. It provides fast and efficient lemmatization and POS tagging. Example:
TextBlob
TextBlob is a more straightforward library for text processing that also provides lemmatization through its built-in functionalities. Example:
StanfordNLP
Stanford NLP is a library developed by the Stanford NLP Group. It provides advanced lemmatization and POS tagging tools, though it requires more resources to set up and run.
Challenges in Lemmatization
Despite its effectiveness, lemmatization comes with several challenges. One of the key issues is ambiguity in word meaning, where words may have different meanings based on their context. For example, the word “lead” can function as both a noun (the metal) and a verb (to guide), and determining the correct lemma depends on the word’s role in the Lightgbm Algorithm . Another challenge is the complexity of morphological rules in languages like English. Irregular forms, such as “went” becoming “go,” add complexity to the lemmatization process, requiring sophisticated algorithms to handle such exceptions accurately. Additionally, language-specific challenges arise because lemmatization is highly language-dependent. Languages like Arabic, Chinese, and Russian pose unique difficulties due to their rich morphological structures and inflectional forms. These languages may require specialized lemmatization techniques to properly process words and derive accurate lemmas. Overall, while lemmatization is a powerful tool in natural language processing, addressing these challenges requires advanced computational methods and algorithms tailored to specific languages and contexts.
Preparing for a Data Science Job Interview? Check Out Our Blog on Data Science Interview Questions & Answer
Conclusion
Lemmatization is a crucial natural language processing approach that improves machines’ comprehension and processing of human language. Lemmatization enhances the performance of several NLP tasks, such as machine translation, information retrieval, and text categorization, by breaking words down into their most basic forms. By considering Data Science Training and meaning of words, lemmatization yields more accurate results than stemming, even though it can be more computationally costly. Lemmatization is still essential to attaining high-quality language processing as NLP develops. Novice and seasoned practitioners can include lemmatization into their NLP workflows by utilizing robust tools and libraries such as NLTK, spaCy, and TextBlob. This will ultimately help create more intelligent computers that comprehend language similarly to humans.




